Pi節點是一個點對點網路(peer-to-peer,P2P),節點透過「單向廣播」傳遞TRANSACTION及SCP_MESSAGE訊息。
如下圖所示,你的節點如何得知最新的區塊資訊,可能有很多條路徑。
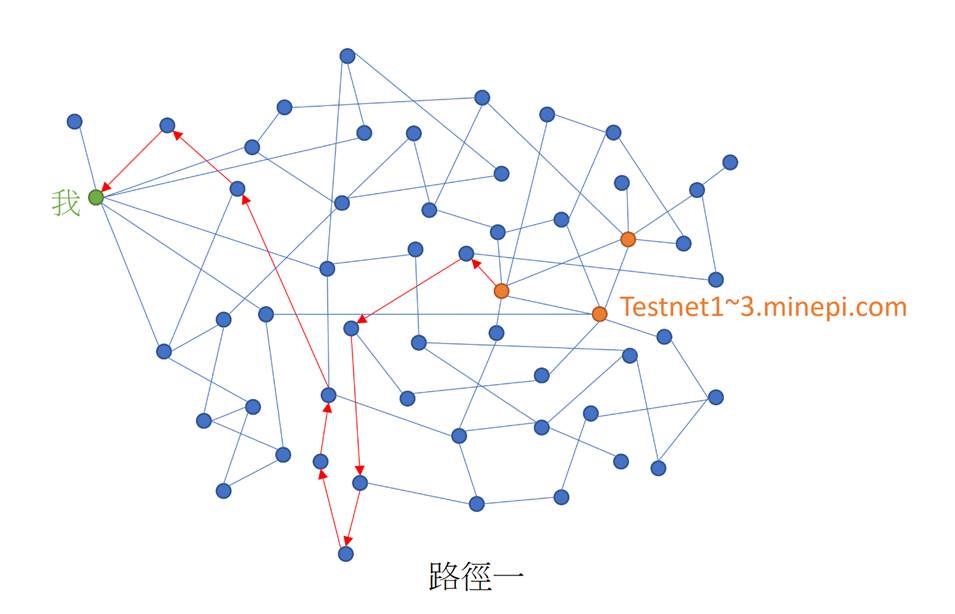
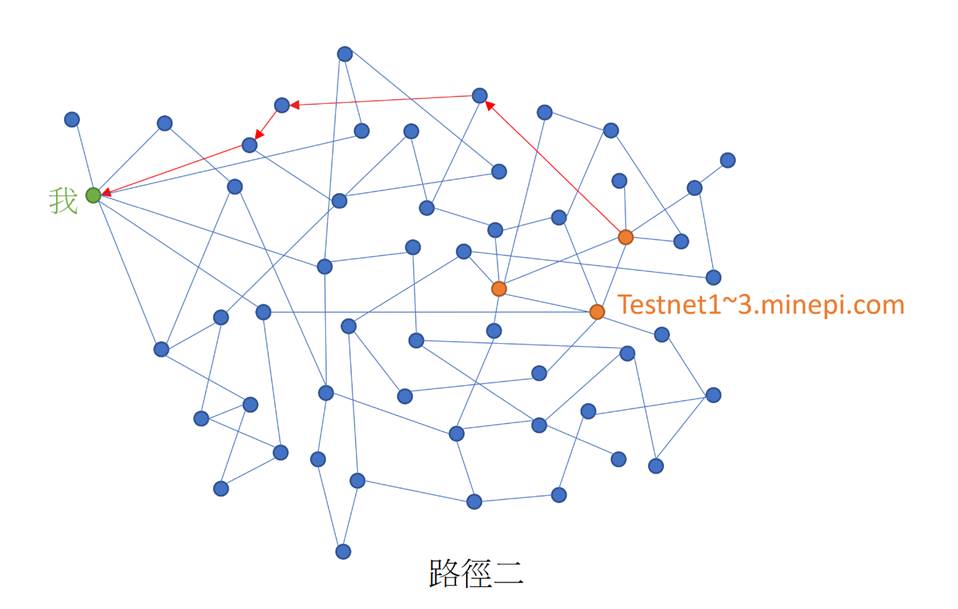
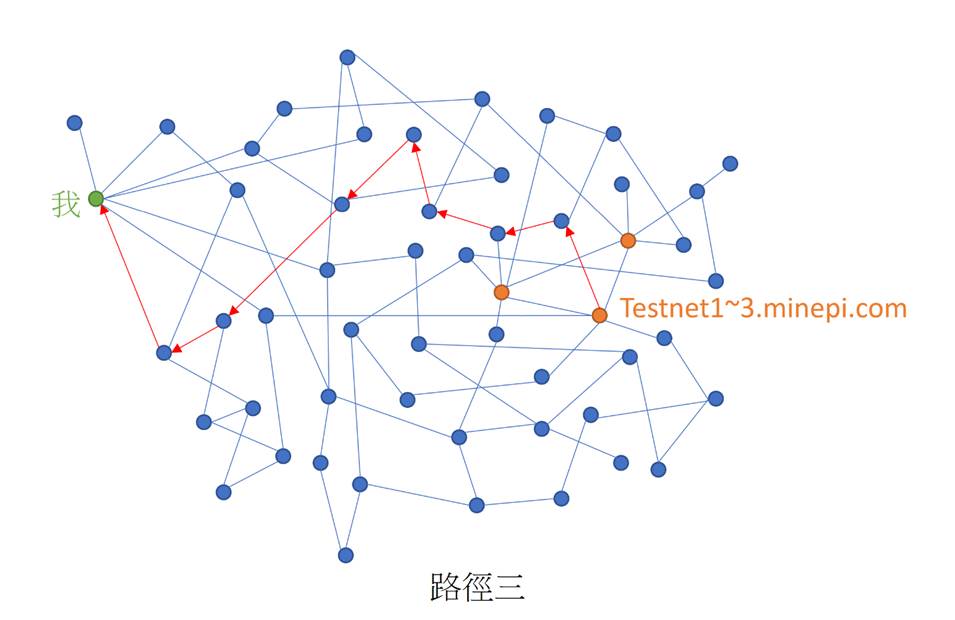
當執行stellar-core http-command 'info',將輸出如下結果:
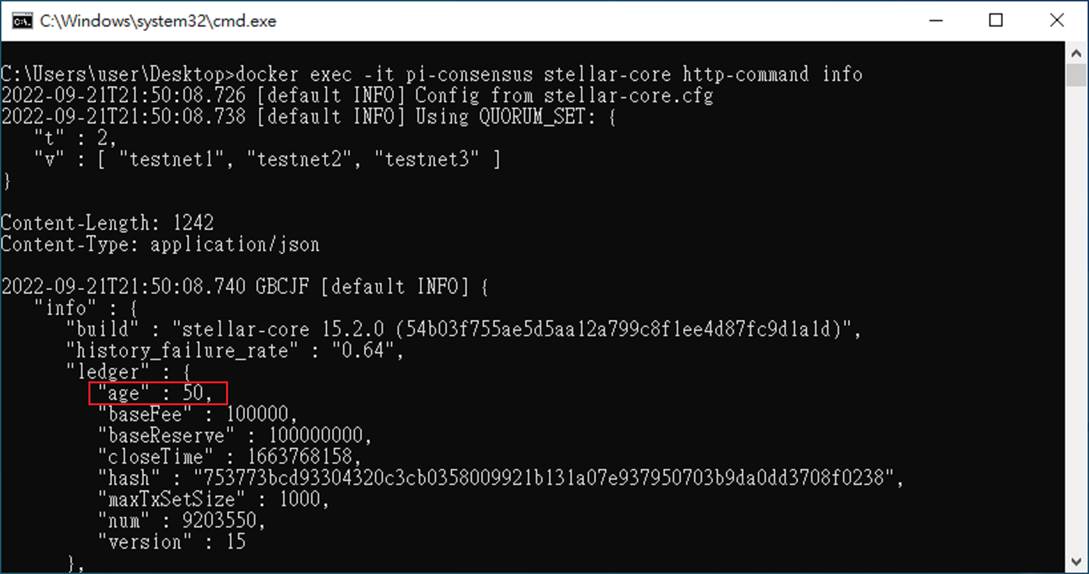
ledger的age是本地賬本(區塊)自關閉以來經過的時間,在正常形況下應少於10秒。
你也可以從%appdata%\Pi Network\docker_volumes\supervisor_logs\stellar-core-stdout---supervisor-xxx_.log中發現,大約5~6秒就會關閉一個區塊。
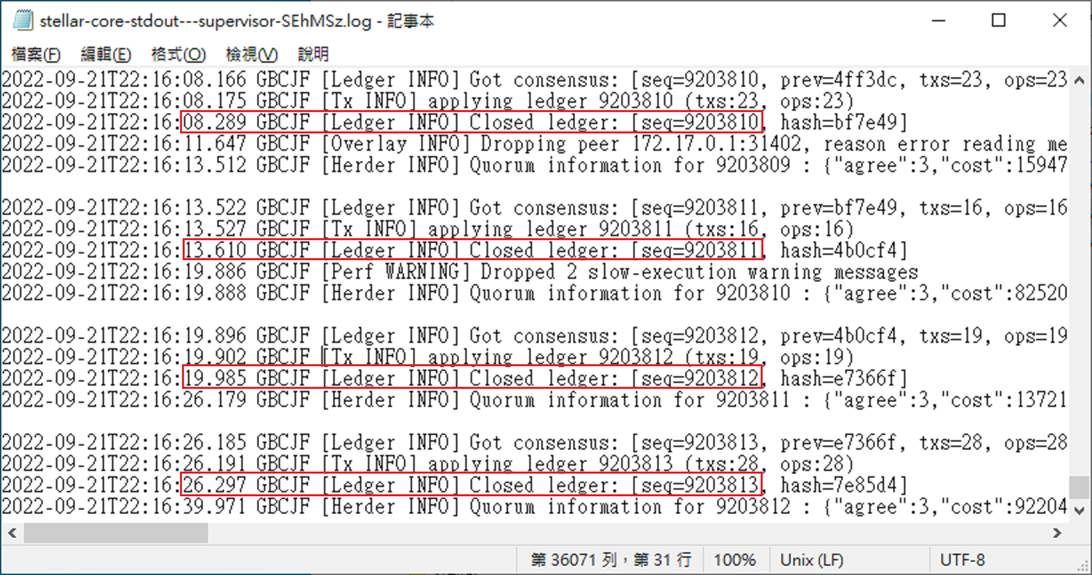
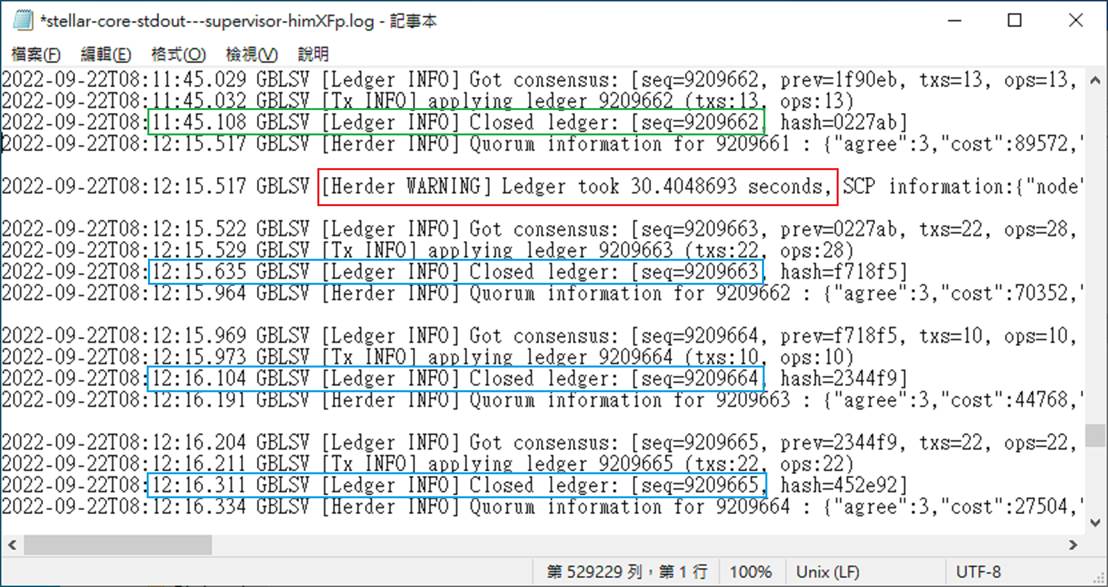
但如果你多檢查幾次,發現age一直增加,你會在log看到「[Herder WARNING] Ledger took xxx seconds」訊息,前後區塊關閉的間隔時間很長,但後面的區塊時間卻都擠在一起,因為資料有所延遲,是後來才一口氣收到。
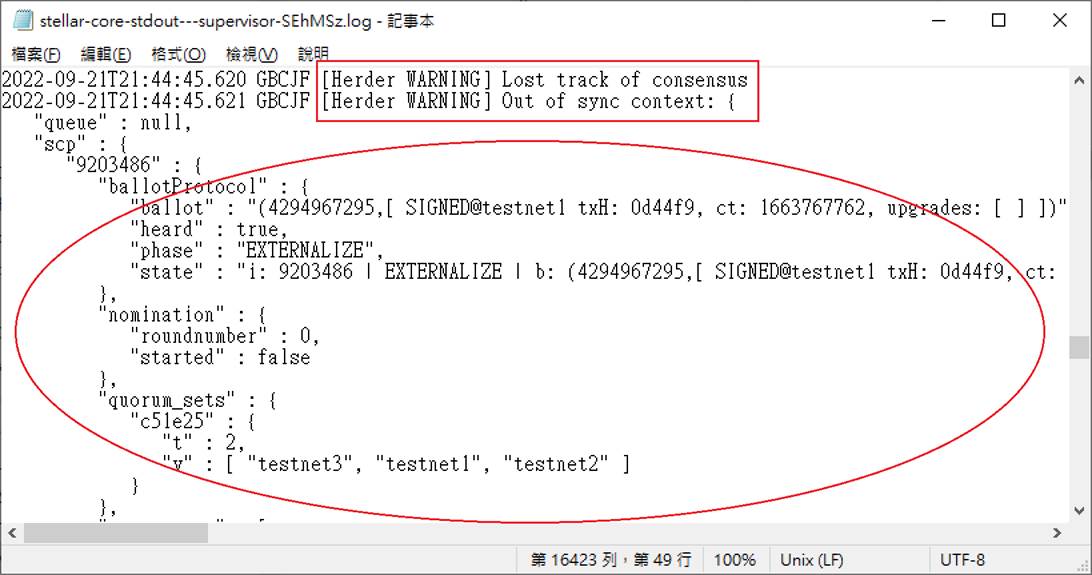
甚至延遲時間再長一點,還會有「[Herder WARNING] Lost track of consensus」、「[Herder WARNING] Out of sync context」訊息。
若超過1分鐘就會進入Catching up的狀態了。

除了極少數是真的因為你的設備或網路有問題,大部分就是運氣不好,如一開頭所講的,在這個P2P網路中,你無法控制資料如何傳遞。
怎麼辦?不需要怎麼辦,這是一個正常現象,你無法改善全世界的網路,而且也跟節點獎勵無關。
但如果你真的很龜毛,實在是受不,可以試試連接其他節點,”也許”狀況能好一點。
先執行stellar-core http-command peers?fullkeys=true,查出目前連接的節點。
結果如下,可看到inbound及outbound兩部分,還有每個節點的id。

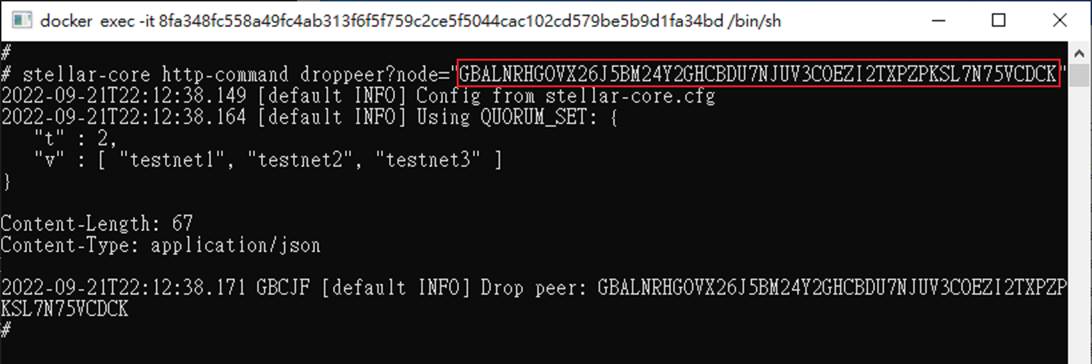
挑一個你看不順眼的,比如latency特別高的,用stellar-core http-command droppeer?node="xxx",指令刪掉它。
xxx就填剛剛查出來的節點id。
如果你刪掉的是一個outbound連線,你的節點馬上就會再重新連上另一個節點;但如果你刪的是inbound連線,就看運氣了,不見得立刻會有人連進來。
換掉幾個節點,看看區塊同步會不會比較順暢。但真的沒必要。
另外,根據觀察,節點連線數量越多,發生區塊延遲的機會越小,因為你的節點有更多不同路徑可以收到廣播訊息。然而因為outbound連線數量的上限是8,通常都是滿的,所以能增加的連線數就剩inbound了。這就容易引起一個誤解,因為我的網路很穩定(這裡的穩定是指區塊都沒有延,這也是誤解),所以inbound連線一直增加。事實上正好相反,因為inbound連線數增加,所以區塊都沒有延遲。
(關於incoming/outoging connections的說明,請參考 https://yuanrui919.github.io/io )